1. 优化器的通用用法
首先引入包:
1 | from torch import optim |
使用例子:
1 | optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) |
优化器类初始化的第一个参数需要是一个 iterable,比如 model.parameters()。列表也是 iterable,比如 [var1, var2]。这个 iterable 里的元素应当是 Variabel(也可以是 dict)。
官方文档里提到一句话:
If you need to move a model to GPU via
.cuda(), please do so before constructing optimizers for it. Parameters of a model after.cuda()will be different objects with those before the call.
也就是说,将模型加载到 GPU 之后再定义优化器(如果这个优化器更新的是这个模型的参数的话)。
1.1. 模型的不同部分使用不同的优化器超参数
实现这样的功能,传入优化器初始化的第一个参数就要是一个元素为 dict 的 iterable,并且 dict 应该有一个 key 是 "params", 其 item 是相应的模块的 parameters。其他的 key 应该是这个优化器初始化的参数名(如 lr, weight_decay 等)。举个例子:
1 | optim.SGD([ |
其中,model.base 部分的学习率为 1e-2,model.classifier 部分的学习率为 1e-3,二者的 momentum 都是 0.9。
1.2. 冻结模型部分层的参数
首先把需要冻结的层的参数设置为不需要求导:
1 | for para in net.frozen_layer.parameters(): |
然后在设置优化器的时候做一下参数筛选:
1 | optimizer = optim.SGD(filter(lambda p: p.requires_grad, model.parameters()), lr=0.01, momentum=0.9) |
1.3. 训练时使用优化器的步骤
这样做:
1 | for input, target in dataset: |
2. 基类优化器 Optimizer
PyTorch 中的优化器都继承自基类 class optim.Optimizer,Optimizer 类的 __init__ 方法定义为:
1 | # __init__ method of optim.Optimizer |
它的两个参数,其中的 params 就是前面说的需要传递进来的 iterable,defaluts 是一个字典,包含了优化器的默认参数(lr, weight_decay 等)。
文档里的说法是:
params: aniterableoftorch.Tensors ordicts. Specifies what Tensors should be optimized.
defaults: a dict containing default values of optimization options (used when a parameter group doesn’t specify them).
这个 defaults 在 Optimizer 类中并没有默认定义,但在它的子类中,即具体的优化器里,会给它一个定义,并传递给 Optimizer 类。举个例子,下面是 SGD 优化器类的 __init__ 函数(optim.SGD),可以看到其中定义了一个 defaults 变量,将该函数的默认参数打包成一个字典,并传递给了父类的 __init__ 函数。
1 | # __init__ method of optim.SGD |
再回来看 Optimizer 类的 __init__ 函数,其中的第 14 行定义了 self.param_groups = [],将会存储该优化器将要优化的参数。
第 16 行 param_groups = list(params) 将参数 params 变成列表,前面提到,params 作为一个 iterable,有三种形式:
model.parameters(): 这里的model是nn.Module对象,它的方法parameters()返回一个generator对象,这当然是一个iterator,把model.parameters()列表化,得到一个列表,其中的元素是torch.nn.parameter.Parameter对象,也就是模型层的权重了。[var1, var2]: 这本来就是个列表,用list()方法后还是原来的列表。其中的var1,var2也是torch.nn.parameter.Parameter对象。[{'params': model.base.parameters()}, {'params': model.classifier.parameters(), 'lr': 1e-3}]: 这是一个列表,其中的元素是字典类型。列表用list()方法还是原来的列表。
这样第 16 行之后 param_groups 作为一个列表,其内部元素的类型有两种:(a) torch.nn.parameter.Parameter 对象;(b) 字典对象,字典里至少有一个 key 为 params 的 item,可能还有其他 key(lr, weight_decay 等)。
第 19 和 20 行做的事情,是让 param_groups 的元素类型必须为字典,如果你不是字典,我就帮你变成字典。如果param_groups 的元素类型为 torch.nn.parameter.Parameter 对象,那么就把 param_groups 这个列表本身作为 key 为 params 的 item 的 value,包装成一个字典,再赋值给 param_groups。
第 22 和 23 行函数 add_param_group 的主要作用是将 param_groups 的东西放进 self.param_groups 中,注意 param_groups 和 self.param_groups 是两个变量。add_param_group 的代码如下:
1 | # add_param_group method of optim.Optimizer |
第 12 行 params = param_group['params'],从前面的分析知道,param_group['params'] 要么是一个列表,要么是一个 iterable 对象(比如 model.base.parameters()),13 - 19 行做的事情,就是不管 param_group['params'] 是什么,都要成为一个列表,并且列表的元素是 torch.nn.Parameter 对象,其实也就是 Tensor。
第 21 - 26 行对 param_group['params'] 里的元素做检查。如果不是叶子 Tensor,就报错。(PyTorch 不保存非叶子节点的 Tensor 的梯度)。
第 28 - 33 行补充 param_group 里的其他键值对,比如 lr, weight_decay 等,如果这些值已经有了,那就不添加,如果没有,就用 self.defaults 里的值。这一点是为了实现不同层使用不同参数的功能。
之后对self.param_groups和param_group中的元素进行判断,确保没有重复的参数。最后将字典**param_group**放进列表**self.param_groups**中
Optimizer 的 zero_grad 函数是将所有参数的梯度置为零,代码如下。其中 detach_()的作用是”Detaches the Tensor from the graph that created it, making it a leaf.”
1 | # zero_grad method of optim.Optimizer |
Optimizer 更新参数主要是靠 step 函数,在父类 Optimizer 的 step 函数中只有一行代码 raise NotImplementedError ,这意味着每个子类都必须实现自己的 step 函数,这个原因很显然,因为不同的优化器更新参数的方式是不同的。后面将会对几个不同的优化器的 step 函数做一下分析。
另外还有两个比较常用的函数:state_dict() 和 load_staet_dict()。
state_dict() 函数返回一个字典,大致如下:
1 | # state_dict method of optim.Optimizer |
保存模型的时候经常也会保存优化器,这时就需要用到 state_dict():
1 | torch.save(optimizer.state_dict(), "optimizer.pt") |
load_state_dict() 函数加载保存的优化器状态:
1 | optimizer_state_dict = torch.load("optimizer.pt") |
3. 一些常用的优化器
3.1. SGD 优化器
类签名:
1 | torch.optim.SGD(params, |
参数含义:
- params (iterable) – iterable of parameters to optimize or dicts defining parameter groups
- lr (float) – learning rate
- momentum (float, optional) – momentum factor (default: 0)
- weight_decay (float, optional) – weight decay (L2 penalty) (default: 0)
- dampening (float, optional) – dampening for momentum (default: 0)
- nesterov (bool, optional) – enables Nesterov momentum (default: False)
计算流程可以参考:

optim.SGD 的代码里主要定义的就是 step() 函数,其主要步骤的实现函数 F.sgd 代码为:
1 | def sgd(params: List[Tensor], |
3.2. Adam 优化器
类签名:
1 | torch.optim.Adam(params, |
参数含义:
- params (iterable) – iterable of parameters to optimize or dicts defining parameter groups
- lr (float, optional) – learning rate (default: 1e-3)
- betas (Tuple**[float, float]**, optional) – coefficients used for computing running averages of gradient and its square (default: (0.9, 0.999))
- eps (float, optional) – term added to the denominator to improve numerical stability (default: 1e-8)
- weight_decay (float, optional) – weight decay (L2 penalty) (default: 0)
- amsgrad (boolean**, optional) – whether to use the AMSGrad variant of this algorithm from the paper On the Convergence of Adam and Beyond (default: False)
计算流程为:

从这个计算流程可以看出,PyTorch 实现里的 Adam 优化器是用 L2 正则化来代替 weight decay 的。
optim.Adam 里具体的函数 F.adam 为:
1 | def adam(params: List[Tensor], |
其中的 step 变量应该相当于公式里的 t。
3.3. AdamW 优化器
类签名:
1 | torch.optim.AdamW(params, |
参数含义:
- params (iterable) – iterable of parameters to optimize or dicts defining parameter groups
- lr (float, optional) – learning rate (default: 1e-3)
- betas (Tuple**[float, float]**, optional) – coefficients used for computing running averages of gradient and its square (default: (0.9, 0.999))
- eps (float, optional) – term added to the denominator to improve numerical stability (default: 1e-8)
- weight_decay (float, optional) – weight decay coefficient (default: 1e-2)
- amsgrad (boolean**, optional) – whether to use the AMSGrad variant of this algorithm from the paper On the Convergence of Adam and Beyond (default: False)]
计算流程为:

从这个流程来看,没有用 L2 正则化来代替 weight decay,并且上来就做了 weight decay,原文的算法流程里是在最后做 weight decay 的,不过这个顺序没有什么影响。
optim.Adamw 里具体的函数 F.adamw 为:
1 | def adamw(params: List[Tensor], |
4. 调整学习率
PyTorch 调整学习率的类都在 torch.optim.lr_scheduler 中,如 torch.optim.lr_scheduler.ReduceLROnPlateau。
4.1. ReduceLROnPlateau
类签名:
1 | torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, |
各个参数的含义如下:
- optimizer (Optimizer) – Wrapped optimizer.
- mode (str) – One of min, max. In min mode, lr will be reduced when the quantity monitored has stopped decreasing; in max mode it will be reduced when the quantity monitored has stopped increasing. Default: ‘min’.
- factor (float) – Factor by which the learning rate will be reduced. new_lr = lr * factor. Default: 0.1.
- patience (int) – Number of epochs with no improvement after which learning rate will be reduced. For example, if patience = 2, then we will ignore the first 2 epochs with no improvement, and will only decrease the LR after the 3rd epoch if the loss still hasn’t improved then. Default: 10.
- threshold (float) – Threshold for measuring the new optimum, to only focus on significant changes. Default: 1e-4.
- threshold_mode (str) – One of rel, abs. In rel mode, dynamic_threshold = best ( 1 + threshold ) in ‘max’ mode or best ( 1 - threshold ) in min mode. In abs mode, dynamic_threshold = best + threshold in max mode or best - threshold in min mode. Default: ‘rel’. “rel” 是 relative 的意思,”abs” 是 absolute 的意思
- cooldown (int) – Number of epochs to wait before resuming normal operation after lr has been reduced. Default: 0. 学习率调整后,在 cooldown 个 epoch 内,学习率不参与调整。即使在这期间指标 在 patience 个 epoch 之内没有提升,也不调整学习率
- min_lr (float or list) – A scalar or a list of scalars. A lower bound on the learning rate of all param groups or each group respectively. Default: 0.
- eps (float) – Minimal decay applied to lr. If the difference between new and old lr is smaller than eps, the update is ignored. Default: 1e-8.
- verbose (bool) – If
True, prints a message to stdout for each update. Default:False.
这个类是直接对 optimizer 的 param_groups 变量的 lr 键进行调整的,可以从源码(torch.optim.lr_scheduler.ReduceLROnPlateau._reduce_lr%3A))得知:
1 | def _reduce_lr(self, epoch): |
使用方法一般如下:
1 | optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9) |
4.2. CosineAnnealingLR
类签名:
1 | torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, |
官方文档给了一个公式说明,但看得不是很明白:

其中的 $\eta_{max}$ 就是优化器的初始学习率,是整个学习率调整过程中余弦值的峰值,$\eta_{min}$ 是最小学习率,手动设置,默认为 0,是余弦值的谷底值。$T_{max}$ 其实就是余弦函数的半周期值。该调整方法对学习率的改变可以做个图看看,代码为:
1 | from torch import optim |
下面是学习率变化曲线,可以看出半周期是 10。

4.3. CosineAnnealingWarmRestarts
带热启动的余弦退火学习率调整机制,参见文章 SGDR: Stochastic Gradient Descent with Warm Restarts。这个机制,是学习率按照余弦函数下降,降到最低点时直接一步回到最高点,所以叫「热重启」。
类签名:
1 | torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, |
官方文档的说明如下:

这里的 $\eta_{max}$ 和 $\eta_{min}$ 的含义和 CosineAnnealingLR 里的含义是一样的。
$T_0$ 的含义是学习率第一次回到初始值的 epoch 位置。如果只说到这里,其实这个 $T_0$ 和 CosineAnnealingLR 里的 $T_{max}$ 的含义是一样的,都是余弦函数的半周期。但之所以这里用的下标是 0 而不是 $max$,并且也强调了是「第一次」回到初始值的 epoch 位置,是因为还要考虑 T_mult 这个参数。
T_mult 参数控制了学习率变化的速度:
- 如果
T_mult=1,那么 $T_0$ 就是余弦函数的半周期(在热重启里,其实只有半个周期,不存在整个周期),即学习率会在 $T_0$, $2T_0$, $3T_0$, $\dots$ 处回到最大值(初始学习率) - 如果
T_mult>1,则学习率会在 $T_0$, $(1 + T_{mult})T_0$, $(1 + T_{mult} + T_{mult}^2)T_0$, $\dots$, $(1 + T_{mult} + T_{mult}^2 + \cdots + T_{mult}^i)T_0$ 处回到最大值 - 如果
T_mult<1,会报错
对比一下二者的学习率变化曲线,代码为:
1 | lr_list = [] |

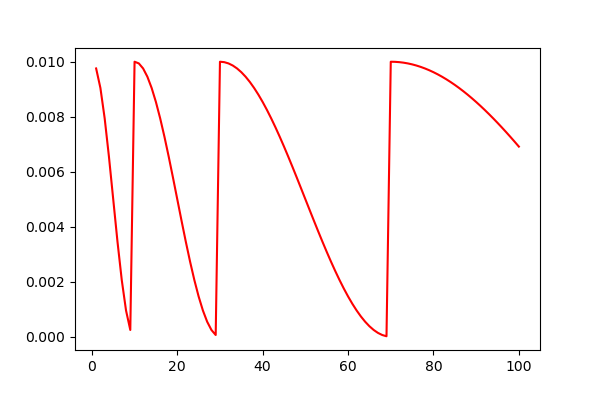
可以看到,当 T_mult=1 时,学习率都是在第 10, 20, 30, … 个 epoch 的时候回到最大值。当 T_mult=2 时,学习率在第 10, 30, 70, … 个 epoch 的时候回到最大值。
在调节参数的时候,一定要根据自己总的epoch合理的设置参数,不然很可能达不到预期的效果,经过我自己的试验发现,如果是用那种等间隔的退火策略(
CosineAnnealingLR和T*mult=1的CosineAnnealingWarmRestarts),验证准确率总是会在学习率的最低点达到一个很好的效果,而随着学习率回升,验证精度会有所下降.所以为了能最终得到一个更好的收敛点,设置T_mult>1是很有必要的,这样到了训练后期,学习率不会再有一个回升的过程,而且一直下降直到训练结束。引用自:pytorch的余弦退火学习率
这个优化器使用时,可以直接使用 step() 更新,如下:
1 | optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9) |
这时是以 epoch 为单位更新,即在一个 epoch 内的所有 batch,都用同一个学习率。
还可以以 batch 为单位更新(这个使用方法来源于官方文档),如下:
1 | scheduler = CosineAnnealingWarmRestarts(optimizer, T_0, T_mult) |
一点疑惑:
关于这个以 batch 为单位,很自然的一种想法是我还是用 step() 更新,但我是每个 batch 的时候都使用一次 scheduler.step(),那么这个和使用 scheduler.step(epoch + i / iters) 会不会是一样的呢?我做了一下对比。
首先是每个 batch 使用 scheduler.step() 函数,把这种情况叫做「step 无参数」:
1 | lr_list = [] |
它的学习率变化曲线如下:
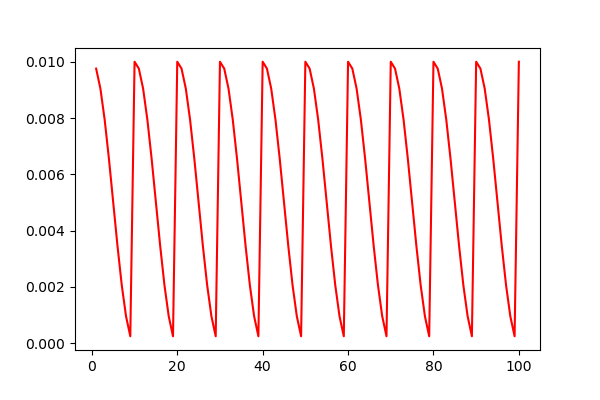
另一种是每个 batch 使用 scheduler.step(epoch + i / iters) 函数,把这种情况叫做「step 有参数」:
1 | lr_list = [] |
它的学习率变化曲线如下所示:
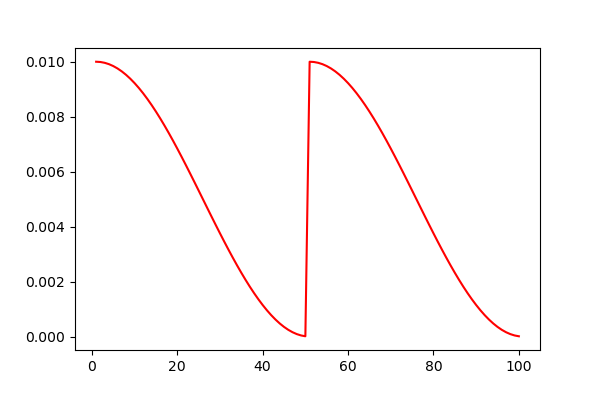
可以看出两种方法对学习率调整的情况实际上是不一样的。分析这两种不同时,我们先把每次调用 scheduler 的 step 函数这个操作叫做「步」。两种方法的 epoch 都设置为 20,每个 epoch 的 batch 数量都为 5。
对于 「step 无参数」的方法,其实是在每一个 batch 都让 scheduler 作用了一步,所以这种方法的学习率变化曲线跟设置 100 个 epoch,每个 epoch 更新一次的曲线是一样的。
对于「step 有参数」的方法,每个 batch 时 scheduler 作用的不是一步,而是 0.2 步(1 除以 batch 数量),这样需要作用 50 个 batch 步数才到达 $T_0=10$,也就形成了曲线里横坐标为 50 的时候学习率回到最高值。
上面的解释如果有点模糊,可以看一下 CosineAnnealingWarmRestarts 的 step 函数源代码:
1 | def step(self, epoch=None): |
这个函数里有个参数 epoch,可以把这个 epoch 理解为上面所说的「步」。使用「step 无参数」方法时,每次调用 step,epoch 参数都会设置为 None,根据第 5 - 6 行,这时候会把 epoch 加 1,也就是说,这时候「步」会加 1(这时「步」一直会是整数)。而使用「step 有参数」方法时,每次调用 step,会执行第 12 - 23 行的代码,这时的「步」不会自动加 1(因为参数已经提供了 epoch 值,epoch 每次加 0.2)。
以上两种情况的不同,仍然觉得没有解释的好,只能根据代码大概意会,等以后再继续学习吧。
4.4. LambdaLR
类签名:
1 | torch.optim.lr_scheduler.LambdaLR(optimizer, |
自定义学习率变化,通过 lambda_lr,一个自定义函数来调整,lambda_lr 不是直接返回学习率,而是返回一个与学习率相乘的因子,来确定最终的实际学习率。lambda_lr 可以是一个函数,也可以是一个函数列表,用于对不同的 param_groups 实行不同的学习率调整机制。lambda_lr 的参数是一个表示 epoch 的单参数。
官方文档的参数说明:
- optimizer (Optimizer) – Wrapped optimizer.
- lr_lambda (function or list) – A function which computes a multiplicative factor given an integer parameter epoch, or a list of such functions, one for each group in optimizer.param_groups.
- last_epoch (int) – The index of last epoch. Default: -1.
- verbose (bool) – If
True, prints a message to stdout for each update. Default:False.
官方示例:
1 | # Assuming optimizer has two groups. |
HuggingFace 的 pytorch_transformers 库里的学习率调整机制就是继承 LambdaLR 类的。