本文为通常所说的 MoCo v1
论文标题:Momentum Contrast for Unsupervised Visual Representatin Learning
作者:Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, Ross Girshick
发表于 CVPR 2020
代码:GitHub
1. 论文里提到的一些基本概念
1.1. 无监督学习的目的
用于预训练一个表征使其可以在微调后用于下游任务
A main purpose of unsupervised learning is to pre-train representations (i.e., features) that can be transferred to downstream tasks by fine-tuning.
——原文 1. Introduction 最后一段
1.2. 代理任务(pretext task)
代理任务是那些我们并不真正感兴趣,只是被用来学习一个好的特征表示的任务
The term “pretext” implies that the task being solved is not of genuine interest, but is solved only for the true purpose of learning a good data representation.
——原文 2. Related Work 第一段
1.3. Instance discrimination task
一个数据集里有 $N$ 张图片,选择一张图片 $X_i$,对这个图片做不同的裁剪和数据增强得到 $X_i^1, X_i^2, \ldots, X_i^m$,则 $m$ 个图片组成的对都是正样本,而它们与其他任意一张图片 $X_j(j \neq i)$ 之间都是负样本。
Instance discrimination task 将每个图片当作一个类别。
a query matches a key if they are encoded views (e.g., different crops) of the same image.
——原文原文 1. Introduction 倒数第二段
1.4. 对比损失(Contrastiv Loss)
首先提出于 LeCun 的论文hadsell2006dimensionality
定义 $\vec{X}$ 为输入,$G_W(\vec{X})$ 为网络输出,即一个特征。两个输入 $\vec{X}_1$ 和 $\vec{X}_2$ 在特征空间的欧氏距离定义为:
则对比损失定义为:
这里的 $W$ 指网络权重,其实也可以不写。$Y$ 是 label,当 $\vec{X}_1$ 与 $\vec{X}_2$ 相似(原文用词为 similar)的时候 $Y=0$,不相似(dissimilar)的时候 $Y=1$。$m$ 表示 margin。
对比损失的含义为:
- 当两个样本相似时,$L = \frac{1}{2}(D_W)^2$,表示两个样本越相似,即欧式距离越小,则损失越小,反之亦然
- 当两个样本不相似时,$L = \frac{1}{2}\{\max \left(0, m-D_{W}\right)\}^{2}$,我们希望网络能辨别出二者是不相似的,即 $D_W$ 越大越好,所以 $D_W$ 前用了负号,$D_W$ 越大,损失越小。当 $D_W$ 比 $m$ 还大时,$m-D_W < 0$,此时损失为 0,也就是说,如果两个向量的距离过大时,这两个样本不参与损失计算。按原文语句:The margin defines a radius around $G_W(\vec{X})$
1.5. Noise-contrastive estimation (NCE)
将多分类问题转化为二分类问题(data and noise),和当前样本属于一类的样本为 data,其他不同类的样本为 noise,只要求能将 data sample 从 noise sample 中区分开就行了。
2. 总体思路
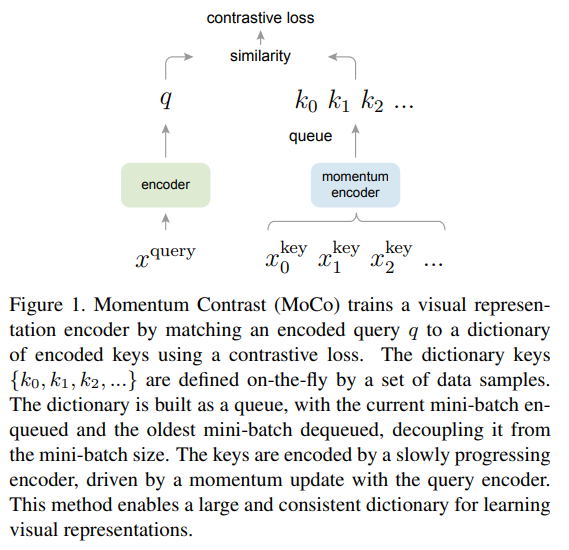
作者将对比学习(contrastive learning)看作一个动态字典(dynamic dictionary)查询问题。字典里的是 key,来自于对整个数据集的采样,key 是数据经过 encoder 得到的特征表示,对比学习的过程是对于一个 query,也用一个 encoder 编码为一个特征,现在这个 query 去字典里做查询(look up),它应该与它的 matching key 相似,与其他的 key 不相似。用于 key 和 query 编码的 encoder 可以相同,也可以不同。
字典最好有两个特性:large and consistant。字典大的好处是可以更好地采样,而 consistant 是指在不同的 iteration 之间,对于字典里同一个 key 编码的特征变化不要太大,也就是说 key 用的那个 encoder 的参数的变化幅度不要太大。
以前的对比学习方法中,字典就是每个 batch,我认为这个 batch 应该是既包含 query 也包含 key 的,也就是说 query 只能跟这个 batch 里的数据计算相似度。这带来的问题是字典的大小受限于 batch size,因为显存的原因,batch size 无法设置得特别大,这样字典也就无法获得 large 这个属性。作者的解决方案是使用一个 queue 来维护这样一个字典,每次更新时,新的 mini-batch 数据入队,旧的 mini-batch 出队,这样字典的容量就跟 batch size 无关,并且可以设置得很大。这种情况下,字典里的 sample 与当前这个 batch 里的 sample(用来当 query)都是 dissimilar pair,都是负样本。
为了 consistant,作者使用了动量(momentum),使得用于字典里 key sample 的 encoder 的权重更新平缓一些。作者提到,对于 query encoder 的权重更新,可以正常使用反向传播规则就 OK,但对于字典里 key 的 encoder 权重更新则不行,因为字典是用 queue 维护的,每次更新时,用于计算的部分 key 样本已经出队列了,一个简单的思路是 key 的 encoder 权重不更新,每次更新了 query 的 encoder 的权重后,将 query encoder 的权重直接复制给 key encoder。作者证明这样是不行的,因为 query encoder 权重更新并不一定平缓,这样导致 key encoder 无法保证 consistant。
定义 query 的特征表示为 $q = f_q(x^q)$,其中 $x^q$ 是 query sample,$f_q$ 是 encoder network,同理可以定义 $k = f_k(x^k)$。记 $f_q$ 和 $f_k$ 的参数分别为 $\theta_q$ 和 $\theta_k$,$\theta_q$ 通过反向传播更新,$\theta_k$ 的更新用动量:
$m$ 的取值范围为 $[0, 1)$,作者提出 $m$ 取得较大的时候效果比较好(文章中取 $m = 0.999$),因为这样 key 的 encoder 更新得比较缓慢,consistancy 更好。
作者给出的示意图如下:
3. 损失函数
本文使用的损失函数是 InfoNCEoord2018representation
对于一个已经编码好的 query $k$ 以及一个 key 字典 ${k_0, k_1, k_2, \ldots}$,可以假设 key 字典中有一个 key (记为 $k^+$) 与 $q$ 是 match 的,其他的都是不match 的。我们希望当 $q$ 与 $k^+$ 相似度高而与其他 key 相似度低时损失函数小,这是很自然的预期。用向量的内积(或点积,dot product)来衡量两个向量的相似度,定义损失函数为:
这像一种 Softmax 函数,只是这时每个样本是一个类别,包括一个正样本 $k^+$ 和其他 $K$ 个负样本。这个损失函数优化的结果是 $q \cdot k^+$ 越大越好。
$\tau$ 是温度系数,用于调整分布的。
4. 代理任务和实现细节
使用的代理任务是 instance discrimanation task,具体来说,对于当前的 mini-batch,对其做两次 augmantation,分别作为构成正样本对的 query 和 key,queue 中的所有样本作为负样本。
使用的 encoder 为 ResNet,在 average pooling 之后加了一层 128-d 的全连接层,其输出作为输入的特征表示,并做了 L2-norm。
作者使用 shuffle BN,起因是发现 BN 层使得模型的表征效果不好,模型在 pretext task 学习中找到了捷径,作者猜测原因是 BN 操作存在 intra-batch communication,这造成了信息泄露。Shuffle BN 是指,用多 GPU 训练,每个 GPU 上的样本独立执行 BN 操作;在用 key encoder $f_k$ 编码当前 mini-batch 产产生的 key (正样本) 时,做一下 shuffle 再分布到不同的 GPU 中(编码后再 shuffle 回来),但对于 query 编码时,不做 shuffle。这样保证了 query 和 对应的 positive keys 在提取特征的时候顺序是不一致的,因此网络无法走捷径。
作者给了伪代码如下:
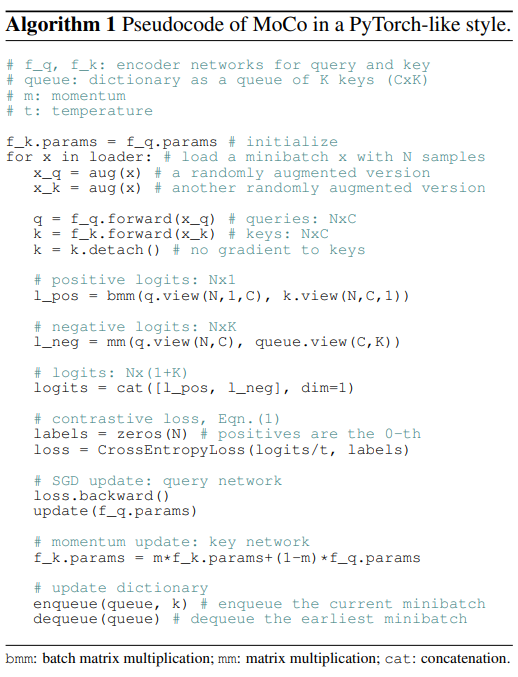
可以看到,key encoder 的权重是 query encoder 初始化的。
l_pos 计算的时候,用的是 bmm(q.view(N, 1, C), k.view(N, C, 1)),这是因为每个 $q$ 只与它对应的那个 $k^+$ 计算内积;而计算 l_neg 的时候,用的是 mm(q.view(N, C), queue.view(C, K)) ,因为每个 $q$ 都要与 $K$ 个 $k^-$ 计算内积。
损失函数是用 CrossEntropyLoss 实现的,labels 给的是全 0,这样只有第 0 个样本对才能对的上 label,其他的都不可能对的上 label,而第 0 个样本总是 positive pair,这样的设计非常巧妙。
5. 实验
作者在 ImageNet 上做无监督预训练后,用 linear probe 的方式在 ImageNet 上训练了分类并在验证集上计算准确率。在网格搜索参数时,发现初始学习率设置为 30,weight decay 设置为 0 是最优超参数设置。作者认为这样的最优超参数表明无监督训练出来的特征分布与有监督训练的特征分布有所不同。
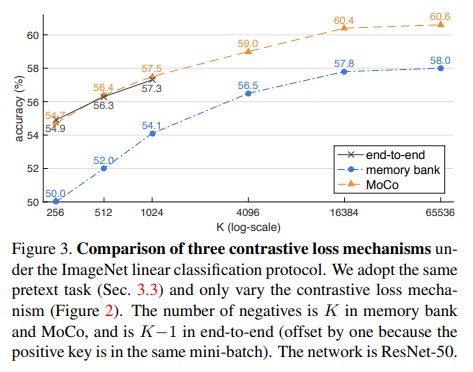
与其他两种对比学习方式做了对比:end-to-end 和 mamory bank。end-to-end 就是最基础的对比学习方式,每个 batch 就充当了字典,包含正样本和负样本,这样的问题是字典大小受限于 batch size。memory bank 论文wu2018unsupervised 中提出的方法,也是本文方法的启发来源,思路大约是,数据集中所有样本的特征表示都放在一个 memory bank 中,每次处理一个 batch 的时候,从 memory bank 中随机选择一批样本作为字典,并且这部分样本是不参与反向传播的;memory bank 中的样本特征只在它上一次被当作 batch 处理的时候更新,这样在经过很多个 batch 之后,前面的 batch 特征可能已经是很久以前的权重计算出来的了,因此 consistant 的特性比较弱。三种方法在 ImageNet 上做 linear probe 的结果对比如下图:
另外一个关于 momentum 大小的实验:
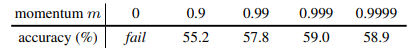
证明 momentum 应该取相对大点的值。
6. 参考文献
hadsell2006dimensionality. Hadsell R, Chopra S, LeCun Y. Dimensionality reduction by learning an invariant mapping[C]//2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06). IEEE, 2006, 2: 1735-1742. ↩
wu2018unsupervised. Wu Z, Xiong Y, Yu S X, et al. Unsupervised feature learning via non-parametric instance discrimination[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 3733-3742. ↩
oord2018representation. Oord A, Li Y, Vinyals O. Representation learning with contrastive predictive coding[J]. arXiv preprint arXiv:1807.03748, 2018. ↩