本文简称 BYOL
论文标题:Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
作者:Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, Michal Valko,来自 DeepMind 和 Imperial College
发表于 NIPS 2020
参考代码:官方代码-TensorFlow, 第三方代码1-PyTorch, 第三方代码2-PyTorch
1. 核心思想
如摘要所说,BYOL 用了两个网络,online network 和 target network,一张图片通过 augmentation 产生两个 view,online network 提取一个 view 的特征来预测 target network 提取的另一个 view 的特征;在更新的时候,online network 通过梯度反向传播更新,target network 通过动量法用 online network 来更新。
本文的独特点在于不需要使用 negative pairs,但并不会带来 collapsed solution。文中表示因为不需要负样本,所以 BOLY 对data augmentation 的要求也没那么高(对比 SimCLR 和 Moco v2),在这一点上更加 roubust,同样,对 batch size 的大小要求也没那么高(对比 SimCLR)。
文章 3. Method 开头两段话讲了本文想法的动机。作者说,如果 online network 和 target network 都根据梯度下降更新(如 SimCLR 那样),这种没有 negative pairs 的方法很容易就坍缩了,即两个网络不管输入是什么,都输出全 0 的向量,这样 loss 直接为 0 了。一个很直接的解决思路是让 target network 的权重随机初始化后直接 fix,只更新 online network,让其来预测 target network 的表示。作者做了这样的实验,发现这样效果并不好(但好于直接使用随机初始化权重的网络)。那既然不能直接固定住 target network,就让它也更新叭,又不能直接用梯度下降更新,那就打 online network 的主意了。因为 online network 一直是在更新的,我们有理由认为这样会使得 online network 对数据的特征表示越来越好,用 online network 的权重来缓慢更新 target network 的权重,这样可以提升 target network 的 representation 的 quality。这样一来,等于说我们用当前 online network 的输出来预测之前 online network 的输出,就有种自举的感觉了,也就是题目 bootstrap 的来源。
2. 总体框架
2.1. 方法介绍
本文的 flowchart 是很简洁的,通过下图可以一目了然:
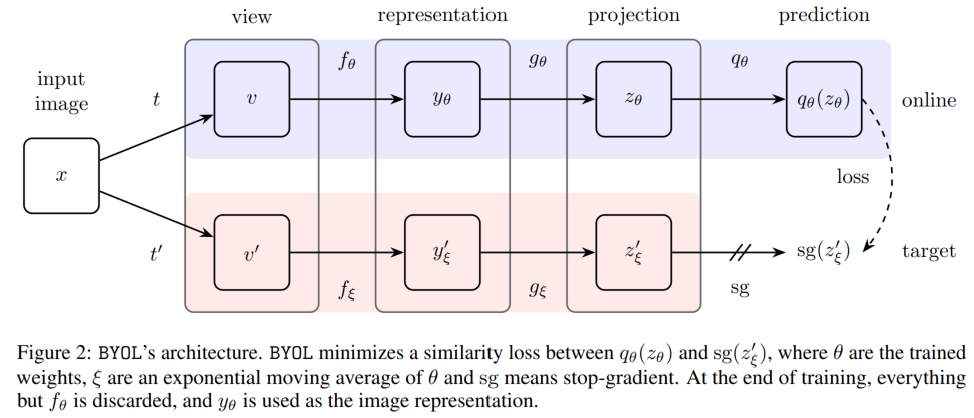
图中的 sg 是 stop gradient 的意思,也就是 $\xi$ 这一条网络不通过梯度下降更新,而是用动量法从 $\theta$ 那里更新的:
$\theta$ 那一条通路里有个 projection head,这在 $\xi$ 那一条通路里是没有的,使得整个结构是非对称的。将 $q_{\theta}(z_{\theta})$ 和 $z^\prime_{\xi}$ 分别归一化后计算 mean square error,即让 $\theta$ 这一路的表示来预测 $\xi$ 这一路的表示。文中记 $\overline{q_{\theta}}\left(z_{\theta}\right) \triangleq q_{\theta}\left(z_{\theta}\right) /\left|q_{\theta}\left(z_{\theta}\right)\right|_{2}$, $\bar{z}_{\xi}^{\prime} \triangleq z_{\xi}^{\prime} /\left|z_{\xi}^{\prime}\right|_{2}$,损失函数是这样写的:
这个等式成立的原因是 $\Vert a \Vert_2^2 = \langle a, a \rangle$,其中 $\langle a, a \rangle = a \cdot a$,也就是向量的点乘。为了简化,记 $a = q_{\theta}\left(z_{\theta}\right)$, $\overline{a} = \overline{q_{\theta}}\left(z_{\theta}\right)$, $b = z_{\xi}^{\prime}$, $\overline{b} = \bar{z}_{\xi}^{\prime}$,则:
上面这个 $\mathcal{L}_{\theta,\xi}$ 是将 $v$ 通过 online network,$v^\prime$ 通过 target network 生成特征在计算损失;接下来还要做一个将 $v^\prime$ 通过 online network,$v$ 通过 target network 生成特征在计算损失,得到 $\widetilde{\mathcal{L}}_{\theta, \xi}$。也就是说,既要让 $v$ 来预测 $v^\prime$ 的特征,又要让 $v^\prime$ 来预测 $v$ 的特征。最后的损失函数是二者相加,得 $\mathcal{L}_{\theta, \xi}^{\mathrm{BYOL}}=\mathcal{L}_{\theta, \xi}+\widetilde{\mathcal{L}}_{\theta, \xi}$。online network 的参数由梯度下降更新:
2.2. 实现细节
数据增强方法用的跟 SimCLR 类似,但感觉更复杂,直接引用原文:
First, a random patch of the image is selected and resized to 224 × 224 with a random horizontal flip, followed by a color distortion, consisting of a random sequence of brightness, contrast, saturation, hue adjustments, and an optional grayscale conversion. Finally Gaussian blur and solarization are applied to the patches.
网络结构方面,最基础的版本是 ResNet-50,也用了更深、更宽的 ResNet 做实验。本文的 projection head 和 prediction head 使用的都是一样的 MLP 结构:Linear (2048 to 4096) — BN — ReLU — Linear (4096 to 256)。作者特意提到,Contrary to SimCLR, the output of this MLP is not batch normalized 。但我在 SimCLR 文中没看到提及 projection head 使用了 BN,在这份实现代码中也没看到用 BN(最新:在官方代码中看到使用 BN 了)。关于 BOYL 中使用 BN 引起了很多讨论,后文会再做一个分析。
优化器使用的是 LARS,学习率策略使用的是 cosine decay without restarts,训练超过 1000 epochs,其中 10 个 epoch 来 warm up。学习率为 $0.2 \times \operatorname{BatchSize}/256$,weight decay 设为 $1.5 \times 10^{-6}$。对于 target network 权重动量更新的 $\tau$,设置从初始的 $\tau_{\operatorname{base}}=0.996$ 逐渐增大到 1,具体来说,其策略为 $\tau \triangleq 1-\left(1-\tau_{\text {base }}\right) \cdot(\cos (\pi k / K)+1) / 2$,其中 $k$ 是 training step,$K$ 是一个 epoch 的最大步数。训练使用的 batch size 是 4096。
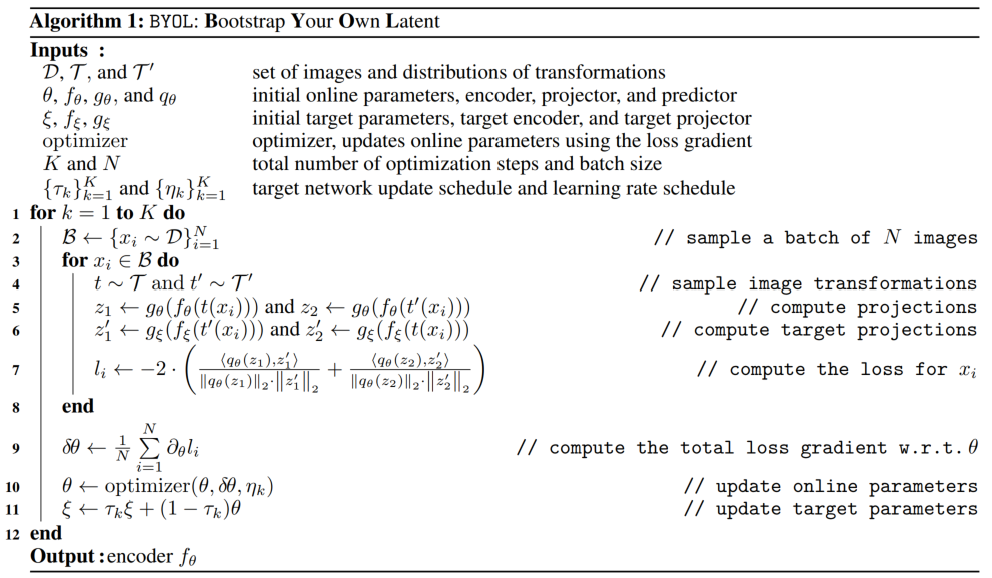
下面是附录里给出的算法流程:
3. 实验结果
3.1. Linear evaluation on ImageNet
使用 linear probe 测试学到的表示在 ImageNet 测试集上的分类准确率:

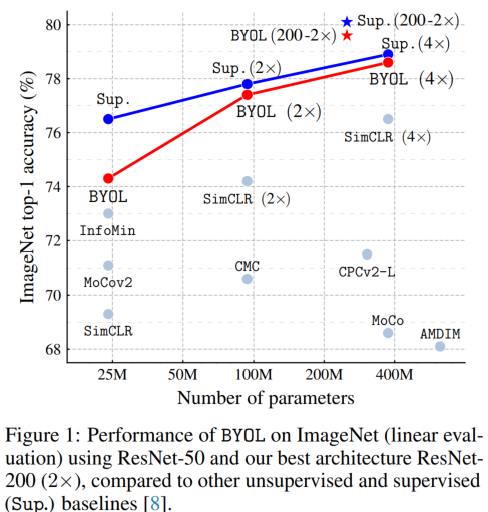
另外给出文中 Figure 1 的直观比较图:
3.2. Semi-supervised training on ImageNet
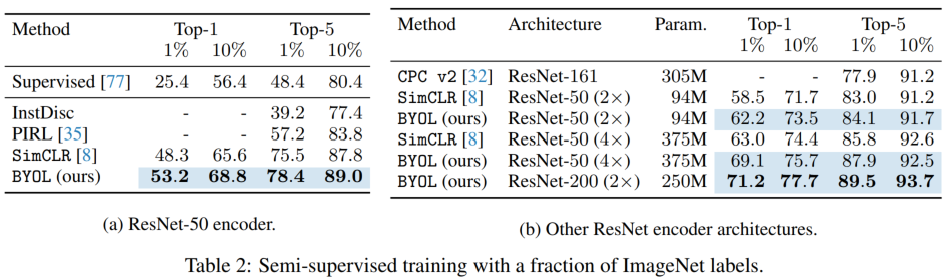
与 SimCLR 中的设置一样,这里也使用 ImageNet 中 1%(每类 ~12.8 张图片) 和 10%((每类 ~128 张图片))的数据对网络进行 fine tune,下面是结果对比:
3.3. Transfer to other classification tasks
迁移到其他数据集上分类。使用的模型为 ResNet-50(SimCLR 使用的是 ResNet-50 x4)。下面是结果对比:
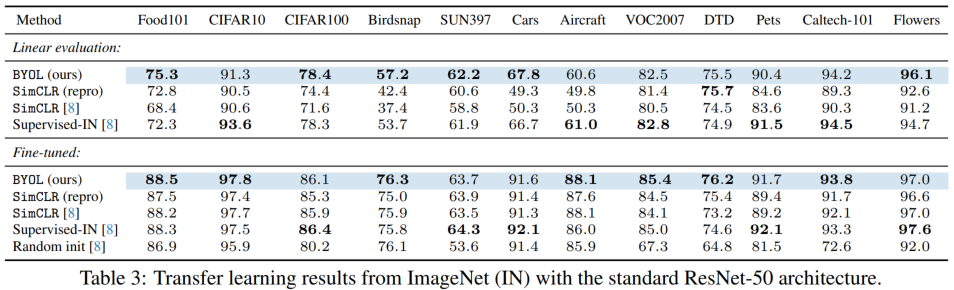
3.4. Transfer to other vision tasks
在 VOC 2012 上做了语义分割,以 mIoU 作为指标;在 VOC trainval2007 上训练目标检测网络 Faster RCNN,在 VOC test2007 上测试,以 AP50 作为指标,结果如下,可以看出,效果好于监督学习预训练的网络。
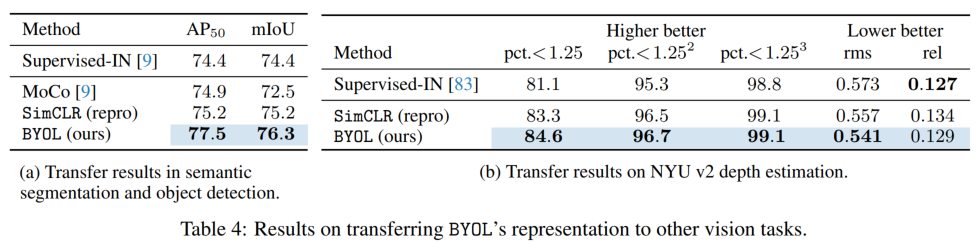
在 NYU v2 数据集上做深度估计实验,结果如下。
4. 消融实验
4.1. Batch size 和 image augmentation
作者提出,因为不需要负样本,所以 BYOL 相比于 SimCLR,不需要很大的 batch size 才能获得比较好的 performance,文中的实验表明,随着 batch size 的减小,BYOL 掉点没 SimCLR 那么厉害。但从图中我们也可以看出,batch size 从 256 降低到 128 时,BYOL 突然掉了很多,这一点在本文的 Review 中也被提到过。
在 augmentation 方面,SimCLR 非常依赖于 color distortion,在 SimCLR 文中也提到过,一张图片的不同 crop 的 color histogram 都比较相近,如果不做 color distortion,模型很容易学到 trivial solution。BYOL 宣称它们的方法是预测 target representation,网络会尽力包含所有需要的信息而不仅仅是学到 color 信息,但这个解释我觉得是比较牵强的。

4.2. $\tau$ 的大小
target network 的权重更新为:
$\tau = 0$ 时,target network 完全跟着 online network,这时候就容易学到 trivial solution,造成模型坍缩;$\tau = 1$ 时,target network 从来不更新,这样也会带来下降。具体的 $\tau$ 值对效果的影响如下(表中数据是 ImageNet 上的 top-1 accuracy):

这个表里给的是 $\tau_{\text{base}}$,前面提到,$\tau$ 的更新是根据 $\tau_{\text{base}}$ 来的:$\tau \triangleq 1-\left(1-\tau_{\text {base }}\right) \cdot(\cos (\pi k / K)+1) / 2$。所以当 $\tau_{\text{base}}=1$ 时,$\tau = 1$,即 target network 从不更新。当 $\tau_{\text{base}}=0$ 时,根据公式 $\tau$ 不一直等于 0,所以这里加了个注释说 $\tau$ 在训练中就恒定设为 0 了。
另外还有一些其他的 ablations,我这里就不写了。
5. 后续讨论
5.1. 一个博客的观点
这篇 来自 untitled-ai 的博客 在复现 BYOL 代码的时候得出两个观点:
- BYOL 中 BN 层是很重要的,如果没有 BN,那么结果跟一个随机初始化的网络没什么差别
- 根据上面一个结论,认为 BYOL 虽然宣称不需要负样本,但 BN 的存在事实上隐式地(implicitly)提供了负样本
博文首先比较了 SimCLR, MoCo v2 和 BYOL 中 projection head (BYOL 中还包括 prediction head) 所用的 MLP 是否包含了 BN 层,给出以下几个方法框架图:
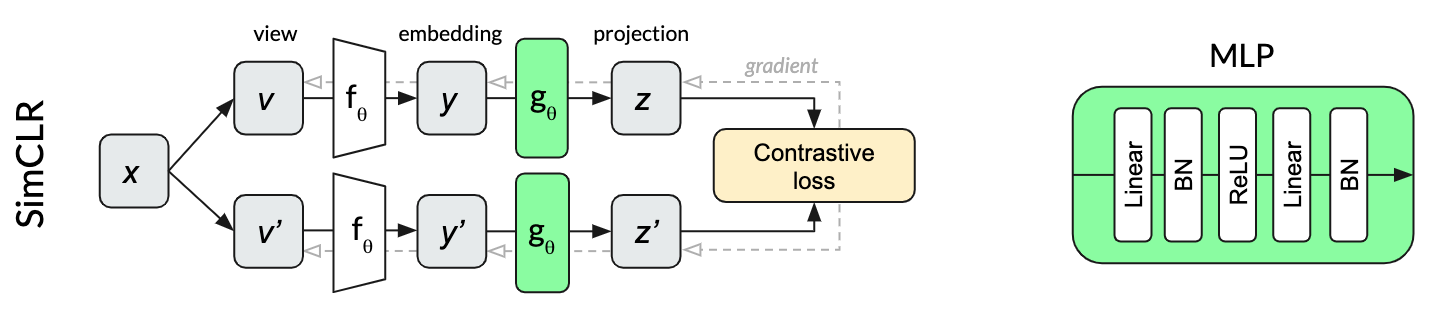
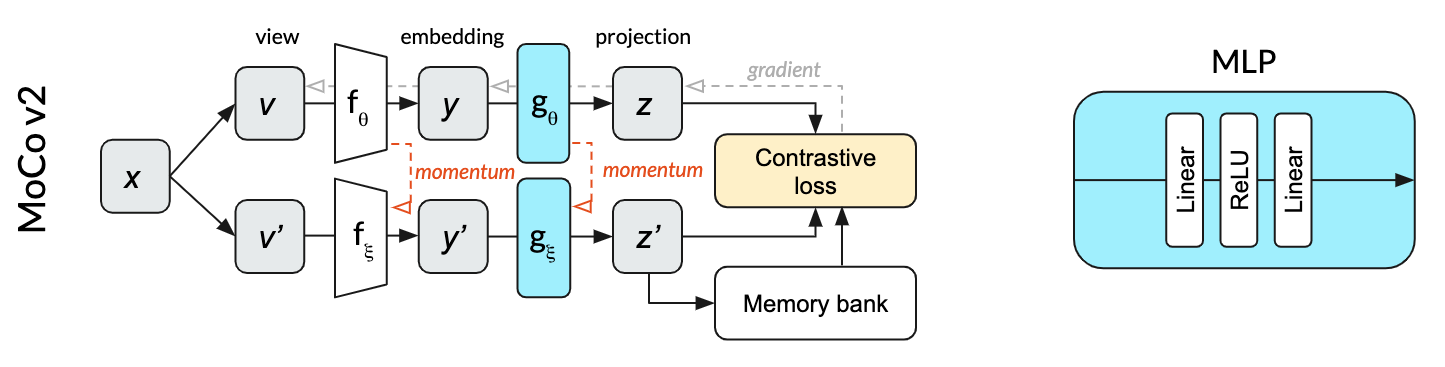
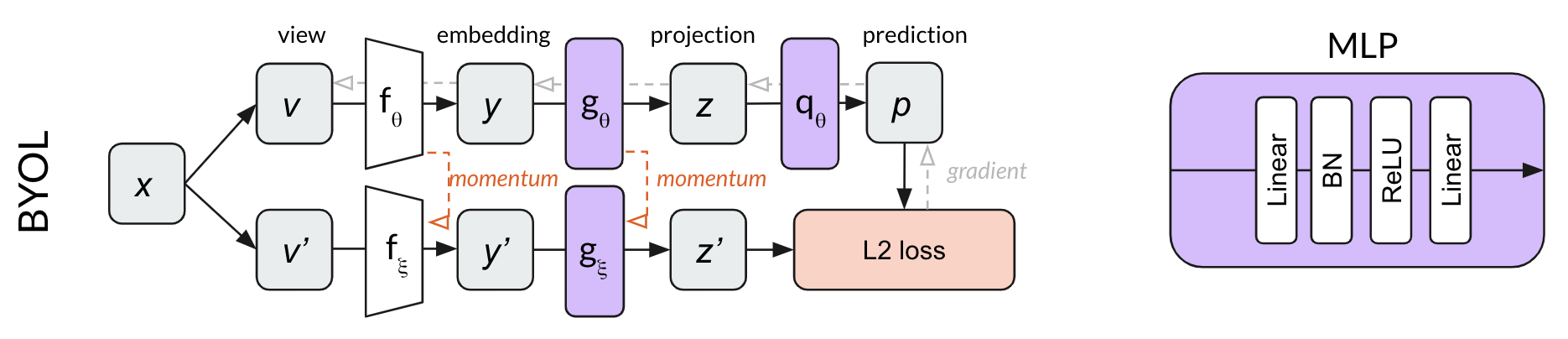
可以看出,SimCLR 的 MLP 中两个 FC 层后面都用了 BN,MoCO v2 则是在 MLP 中一个 BN 都没用,而 BYOL 中的 MLP 则是第一个 FC 后面用了 BN,而第二个 FC 后面没用 BN。
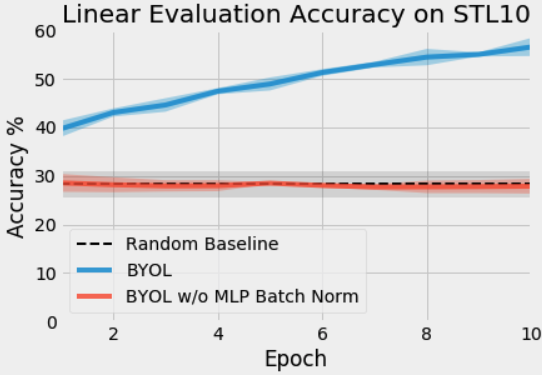
博文的作者基于 MoCo 的代码修改来复现 BYOL,因此 MLP 中是不含 BN,结果却发现 BYOL 中如果 head 不用 BN,初始时候直接就模型坍缩了,与随机初始化网络的结果没什么区别,见下图。需要说明的是,博文作者复现使用的是 ResNet-18 作为 encoder,在 STL-10 数据库上训练和测试,使用 SGD 优化器,batch size 设置为 256。
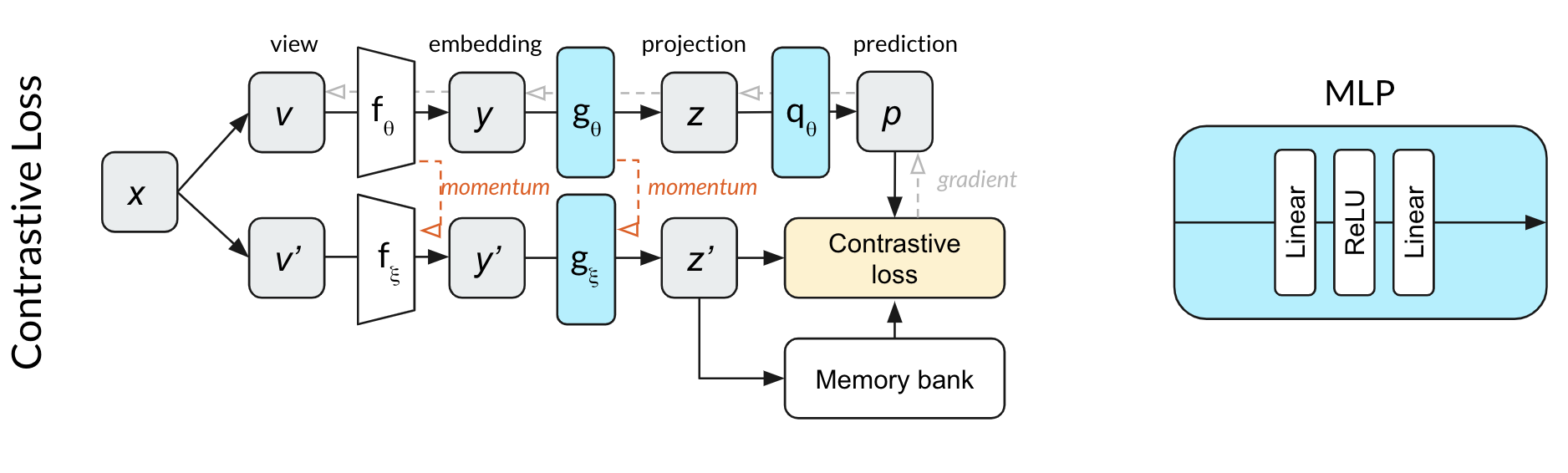
为了探究为什么不用 BN 会造成这样的结果,作者修改了损失函数,显式地使用负样本对和对比损失,形成下面这个比较像 MoCo v2 的结构,当然与 MoCo v2 不同的是,online network 多了一层 prediction head。
这下发现,在初始 10 个 epoch 并没有发生坍缩,准确率相比于随机初始化网络有了较大提升。接着作者又做了其他几个实验,包括使用 Layer Norm,以及是否在 projection head 和 prediction head 中使用 BN,结果如下:
| Name | Projection MLP Norm | Prediction MLP Norm | Loss Function | Contrastive | Performance |
|---|---|---|---|---|---|
| Contrastive Loss | None | None | Cross Entropy | Explicit | 44.1 |
| BYOL | Batch Norm | Batch Norm | L2 | Implicit | 57.7 |
| Projection BN Only | Batch Norm | None | L2 | Implicit | 55.3 |
| Prediction BN Only | None | Batch Norm | L2 | Implicit | 48 |
| No Normalization | None | None | L2 | None | 28.3 |
| Layer Norm | Layer Norm | Layer Norm | L2 | None | 29.4 |
| Random | — | — | — | None | 28.8 |
根据表格数据得出以下几条发现:
- 因为没使用对比损失,所以 BYOL 很依赖 BN
- BN 使得同一批次不同样本之间的信息得到交互,这是一个关键因素,LN 因为只与自己本身做 norm,因而效果也不好
- projection head 和 prediction head 二者中有一个用 BN 就能带来效果上的提升,但 projection head 中的 BN 提升效果更明显
博文中说,为什么 BN 能阻止模型坍缩呢,因为坍缩的表现就是所有输出都是 $[1, 0, \cdots, 0]$ 这样的向量,而 BN 的 normalization 正是避免这样的情况发生的。另外,博文认为,BN 隐式地提供了负样本,这个负样本就是一个 mini-batch 里的 average image,所有的样本都会跟这个 average image 做对比。
博文还做了进一步验证,在每个 mini-batch 中,把正样本对和负样本对(虽然 BYOL 中是不计算负样本对的,但每个 mini-batch 中还是可以跟 SimCLR 一样选择正负样本对)的 projection head 的输出特征(也就是上面 BYOL 图中的 $z$ 和 $z^\prime$)计算 cosine similarity,如果模型没有坍缩,那么正样本对的 cosine similarity 应该大于负样本对,下面的结果也证实了这一点:
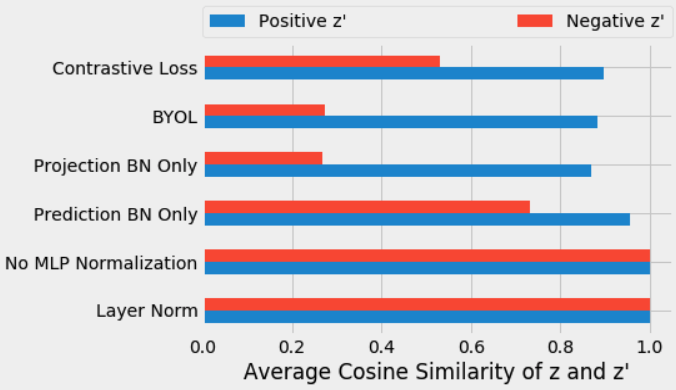
注意,以上的结果都是只训练了 10 个 epoch 的模型结果,作者发现继续训练的话,即使 MLP 中不用 BN,模型也能从坍缩中走出来,这被作者认为是 ResNet 中的 BN 的作用。
如果把 ResNet 中的 BN 也移除了呢,那模型就完全不能 work 了。但等等,还不是这样,到此为止,上面的实验都是用了 SGD 优化器中,博文作者在咨询了 BYOL 论文作者后,他们说你要是用 LARS 优化器就不会因为没有 BN (指整个网络一个 BN 都没有)而坍缩了,作者试了一下发现确实是这样,但效果确实比使用 BN 变差了,并且这样很依赖精细调参。所以总的来说,还是 BN 起到了很大的作用。
博文的附录中还有几个 longer training 的实验,一是比较了去掉 MLP 中 BN 的情况,如下图。可以发现,只要 ResNet 中还有 BN,模型就不会坍缩,并且这种情况下使用 LARS 优化器要比 SGD 优化器更好,但还是比不过 MLP 中加了 BN 的情况。
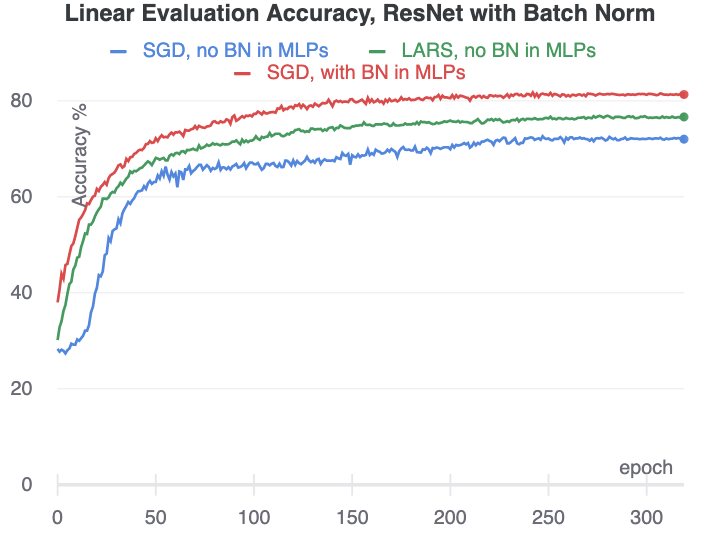
另外一个实验是把 ResNet 中的 BN 全部换成 Group Normalization,这样如果 MLP 中不加 BN,那整个网络就都没有 BN 了,实验对比如下。实验结果表明,如果整个网络里一个 BN 都没有,用 SGD 优化器就直接坍缩了;如果用 LARS 优化器,需要调参,学习率在 0.2 的时候没问题,学习率变成 0.1 的时候就又坍缩了,这说明网络中没有 BN 的话,即使用 LARS 优化器,也得精细调参才行。而如果 MLP 中有 BN,在 ResNet 也没有 BN 的情况下,模型仍然能训练得起来。
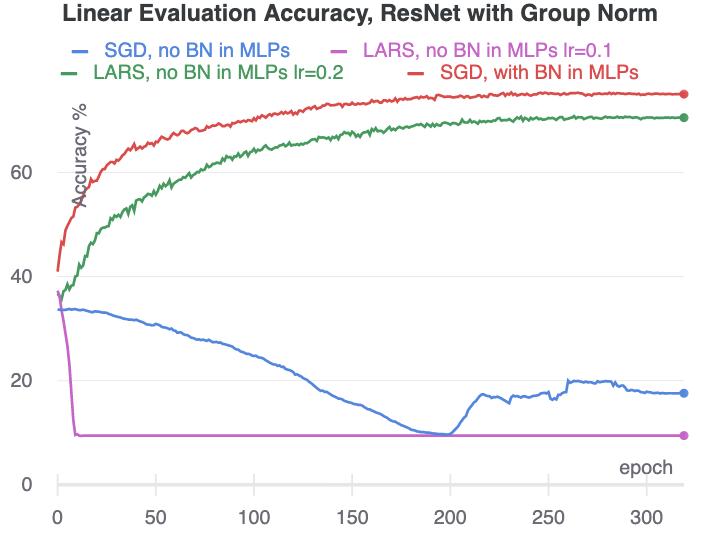
附录中还提出了在不用 BN 时防止模型坍缩的方法,包括使用 Weight Decay 和 Weight Standardization,这里就略过了。
5.2. 论文作者对博文的回应
在博客出来之后,BYOL 的作者专门写了篇文章回应,标题是 BYOL works even without batch statistics,文章标题还特意把 even 这个词给斜体了。文章从两个方面反驳博文中对 BN 作用的讨论。
首先给出一个表格,展示了大量的消融实验(实验参数设置与 BYOL 原文中相同),如下所示。如果能保持 Encoder 中有 BN,那么模型效果其实不会受到太大影响;如果移除 Encoder 中的 BN,但保留 Projector 或 Predictor 中的 BN,那么模型效果会有所下降;如果把所有模块的 BN 都移除了或者用 LN 代替,那么 BYOL 就坍缩。作为对比,SimCLR 中的 BN 移除造成的影响没那么大,但把 BN 都移除时,SimCLR 也训练不起来。
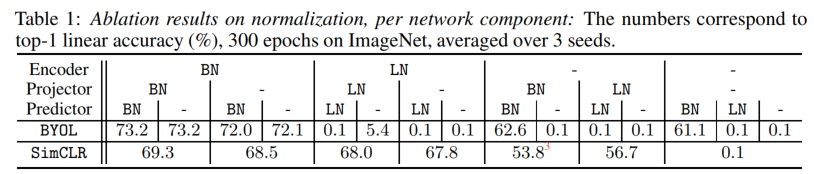
5.2.1. 随机初始化的模型 BYOL 训不好,BN 弥补了这个问题
根据以上实验,作者认为 BN 发挥作用的主要部分在 Encoder 中,进而猜想这表明 BN 的作用并不是隐式地带来负样本,而是对模型初始化起到了很好的补偿作用。也就是说,作者认为,随机初始化的模型是一个 improper initialization,直接训练的话就会把模型训歪,但是如果用了 BN,就可以弥补随机初始化带来的问题。
为了证明这个猜想,作者说那我就去掉 BN,但我又要保留 BN 补偿随机初始化的作用,用原文中的话说,叫 to mimic the effect of BN on initial scalings and training dynamics, without using or backpropagating through batch statistics. 文中在训练前先前向计算一下网络,通过 mini-batch 的数据计算来初始化一下 BN 中的可训练参数 $\gamma$ 和 $\beta$,在训练网络的时候,保留这两个参数(这样就保留了 BN 的 scaling 作用),但不用计算 mini-batch 的统计信息,作者认为这样就等于是 remove BN 了(具体操作细节还是看文章中的描述)。这样的操作使得模型在没有 BN 的情况下达到了 65.7% top-1 accuracy in the linear evaluation。PS: 我是不认可这个说法的,这个实验虽然去掉了 BN,但在训练前的前向过程中计算了 mini-batch 的统计信息用于初始化 $\gamma$ 和 $\beta$,这之间引入了什么就说不清了。
5.2.2. 使用 Group Normalization 和 Weight Standardization 可以提升效果
上面说的去掉 BN 也可以不坍缩,但结果相比于使用 BN 的 74.3% 还是有些差距的。作者又做了新的实验,这次用了 GN 代替所有的 BN (这样就真的不会跟 mini-batch 中的其他数据产生交互了),然后又对每一层用来 WS,再经过精细调参(which 我觉得很没意思),在训练了 1000 个 epoch 之后,终于把结果提升到 73.9%。
什么是 Weight Standardization 呢,我直接引用原文的话了,因为我实在不想写了。
WS normalizes the weights corresponding to each activation using weight statistics. Each row of the weight matrix $W$ is normalized to get a new weight matrix $\widehat{W}$ which is directly used in place of $W$ during training. Only the normalized weights $\widehat{W}$ are used to compute convolution outputs but the loss is differentiated with respect to non-normalized weights $W,$
where $\mathcal{I}$ is the input dimension (product of input channel dimension and kernel spatial dimension); we set $\epsilon = 10^{-4}$.
这篇回应的文章我不太赞同,虽然做了这么多实验说 BYOL 不依赖 BN,但是用了这么多复杂的技术和 trick 以及调参,已经说明 BN 的重要性了(简单地使用 BN 就能代替这么多操作哦),这么多复杂操作只能说明 BYOL 不 robust 了。这篇回应文章应该还是要维护 BYOL 文中提出的卖点:不需要使用负样本。我觉得这个卖点对实际使用没什么太大的帮助(对发文章来说还是必要的),还不如老老实实承认 BN 确实有用呢。
6. 写在最后
写这个笔记的时候,正值学校因为疫情封校封楼(3 月 9 号封校,3 月 12 号封楼)。在寝室蜗居数日,并眼看着每日新增病例,心情不免比较低沉。下图是出去核酸检测路上拍的照片,只有核酸检测时才能看看春天了。惟愿疫情早日结束,大家都健健康康。
