这里只记录使用 torch.nn.parallel.DistributedDataParallel 进行多卡训练,使用 torch.nn.DataParallel 的方法已经不被 PyTorch 官方推荐了,因此不做赘述。
1. 原理
DDP加速的原理是通过启动多个进程,提高同时训练的 batch size 来增加并行度的,每一个进程都会加载一个模型,用不同的数据进行训练之后得到各自的梯度,然后通过 Ring-Reduce 算法获得所有进程的梯度,然后进行相同的梯度下降。注意在训练前和训练后,所有进程的模型参数都是同步了的。
Ring-Reduce 是很简单理解的一个算法:每个进程都从左手边获得一份梯度,然后从右手发送一份梯度(一份指的是一个 GPU 得出的梯度),经过 n 次迭代之后,所有进程都获得了相同的完整的梯度。如下图,假设梯度 $\nabla w$ 是 GPU0 算出来的,第一次 $\nabla w$ 被发送到 GPU1,第二次被 GPU1 发送到 GPU2,第三次被 GPU2 发送到 GPU3,第四次被发送到 GPU4,第五次被发回给 GPU0。这样每个进程都只需要接收一个,发送一个,而且能够清楚知道什么时候结束。
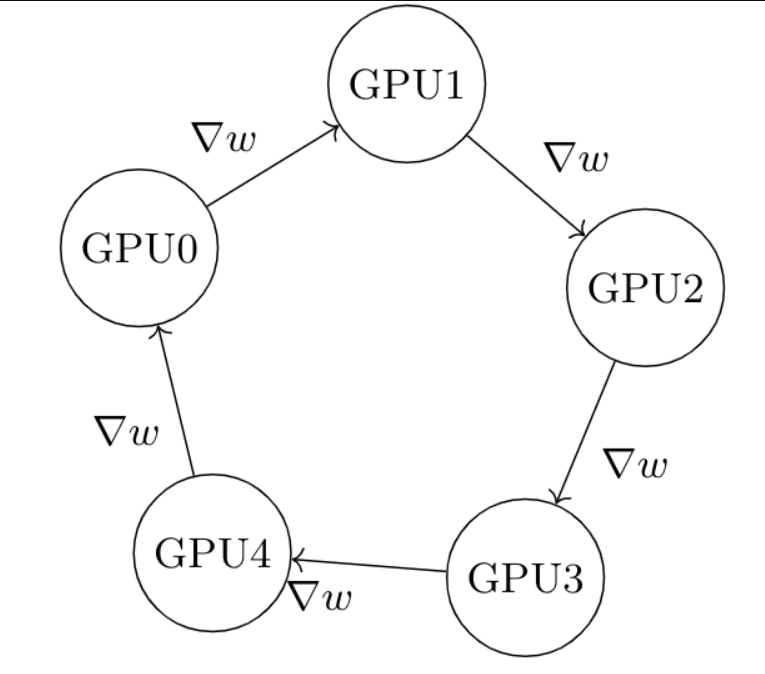
原理部分来源于 这个博客
2. 基本概念
world_size:全局并行的进程数,一般一个 GPU 上一个进程,所以可以理解为使用的所有 GPU 数目。单机多卡时,world_size就是这台机器上的 GPU 数目;多机多卡时,world_size就是机器数×每台机器上的 GPU 数目。可以通过torch.distributed.get_world_size()获得world_sizerank:当前进程在全局的序号,全局指的是所有机器上的进程,rank=0的进程是 matser 进程,可以通过torch.distributed.get_rank()获得当前进程的ranklocal_rank:当前进程在这台机器上的序号,单机多卡时,local_rank与rank其实是一样的
3. 使用流程
首先给出启动方式:
1 | python -m torch.distributed.launch --nproc_per_node=n_gpus train.py |
3.1. 准备工作
1 | import torch |
使用 torch.distributed.launch 启动时,将会为当前主机创建 nproc_per_node 个进程,每个进程独立执行训练脚本。同时,它还会为每个进程分配一个 local_rank 参数,表示当前进程在当前主机上的编号,需要在 argparse 中加上 --local_rank 来接收这个参数:
1 | # 这个 local_rank 不用管,由 torch.distributed_launch 来分配 |
如果在命令行启动时使用这样的命令:
那么当前进程的
local_rank不会传递给args.local_rank,而是要通过os.environ['LOCAL_RANK']获得
接下来指定当前使用哪块 GPU:
1 | local_rank = args.local_rank |
下面进行 DDP 的初始化,用 torch.distributed.init_process_group
torch.distributed.init_process_group的函数签名为:
2
3
4
5
6
7
8
init_method=None,
timeout=datetime.timedelta(seconds=1800),
world_size=- 1,
rank=- 1,
store=None,
group_name='',
pg_options=None)我们比较关注的参数是
bakcend,init_method,world_size,rank
backend:使用什么通信后端,有mpi,gloo和nccl可选,在 Nvidia 显卡中一般使用nccl
init_method:当前进程组的初始化方式,这个不太明白是干啥的,在默认情况下(init_method=Noneandstore=None),init_method会被设置为"env://",表示使用读取环境变量的方式进行初始化,单机多卡时这样使用应该是没问题的,即不指定这个参数。也可以手动指定为init_method="env://"。这样默认时,这个进程会自动从本机的环境变量中读取如下数据:
MASTER_PORT:rank0 机器上的一个空闲端口
MASTER_ADDR:rank0 机器的地址
WORLD_SIZE:这里可以指定,在init函数中也可以指定
RANK:本机的rank,也可以在init函数中指定
world_size:就是全局进程数,在store=None的时候是可以不设定的,我看到的很多代码里都没有设置。当然也可以通过args传参来给定,或者设置为int(os.environ['WORLD_SIZE'])
rank:当前进程的全局序号,这个在store=None的时候也可以不设定,并且很多代码里都没设定。当然,也可以设置为int(os.environ['RANK']),在单机多卡时,应该也可以设置为local_rank
综上所述,在单机多卡训练时,直接用下面的方式初始化是没什么问题的:
1 | # dist is torch.distributed |
init_process_group (可通过 dist.is_initialized() 判断) 之後可以用 dist.get_world_size() dist.get_rank() 等方法獲得需要信息,不需要依靠 args 了。
我对 init_method 的理解
init_method 一般有 env:// 和 tcp:// 两种选择。
对于
env://,一般直接使用dist.init_process_group(backend="nccl", init_method="env://")就可以了(甚至init_method也不用显示给出),world_size和rank两个参数可以不给出(至少在单机多卡时是可以的)。在多级多卡的情况下是否要给出,我还不太清楚,给出的话应该也可以通过命令行来传输的,这部分可以参考 MoCo 的代码(MoCo 的代码中,通过命令行给出机器数和当前机器的编号,再转换成world_size和rank给init_process_group方法)。单机多卡运行:
1
python -m torch.distributed.launch --nproc_per_node=n_gpus train.py
多机多卡运行:
1
2
3
4
5
6
7
8node 1
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE
--nnodes=2 --node_rank=0 --master_addr="192.168.1.1"
--master_port=1234 train.py
node 2
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE
--nnodes=2 --node_rank=1 --master_addr="192.168.1.1"
--master_port=1234 train.py多机多卡时,需要额外指定
--nnodes,--node_rank,--master_addr,--master_port参数,这几个参数和--nproc_per_node都由torch.distributed.launch来处理,在代码中不需要用args来接收。对于
tcp://,需要指定主进程的 IP 和端口号,使用dist.init_process_group(backend="nccl", init_method="tcp://192.168.1.1:1234")这样的设置,world_size和rank需不需要设置不太清楚,但我看到的代码很多都设置了(比如 MoCo)。用这种方式初始化的时候,不需要在脚本中用
torch.distributed_launch来启动。但要指定机器数量和当前机器的编号,然后转换成world_size和rank传递给init_process_group。可以参见 MoCo 的代码
3.2. 包裹模型
在包裹模型前,首先要把模型放到单块 GPU 上:
1 | device = torch.device("cuda:{}", local_rank) |
3.3. 数据并行
DDP 同时起了很多个进程,但是他们用的是同一份数据,我们当然希望每个 GPU 上使用不同的数据,这时需要一个 sampler 自动为每个进程分配不同的数据:
1 | # from torch.utils.data.distributed import DistributedSampler |
DistributedSampler 还有一个参数是 num_replicas,默认是 world_size,所以一般也不用手动设置
3.4. 训练
我更愿意把一个 epoch 的训练过程包装成一个函数:
1 | def train_on_epoch(model, train_loader, criterion, optimizer): |
现在是训练用的函数:
1 | for epoch in range(epochs): |
每个 epoch 开始之前,要先用 train_sampler.set_epoch(epoch) 随机 shuffle 一下数据,要不然每个 epoch 里给 GPU 分配的数据都是一样的。
3.5. 保存模型
只在主进程中保存模型,并且保存的是 model.module
1 | if dist.get_rank() == 0: |
3.6. 其他注意事项
验证集如何处理
验证集一般在一个 epoch 的训练之后,可以使用多卡,也可以使用单卡。
- 使用多卡时注意也要使用
DistributedSampler - 使用单卡时只在一个进程上操作,注意此时要用
model.module(inputs)而不是model(inputs)来前向传播,并且其他进程通过torch.distributed.barrier()来等待主进程完成 validation
BN 层处理
BN 中有 moving mean 和 moving variance 这两个 buffer,这两个 buffer 的更新依赖于当前训练轮次的 batch 数据的计算结果,在普通模式下,每张卡单独计算自己的 moving mean 和 moving variance,在单卡上的 batch size 比较小的时候,这样的 BN 实际上没有起到应有个的效果。
实现真正的多卡 BN,DDP 中可以使用 SyncBN利用分布式通讯接口在各卡间进行通讯,从而能利用所有数据进行 BN 计算。为了尽可能地减少跨卡传输量,SyncBN 做了一个关键的优化,即只传输各自进程的各自的 小batch mean 和 小batch variance,而不是所有数据。具体流程如下:
- 前向传播
- 在各进程上计算各自的
小batch mean和小batch variance - 各自的进程对各自的
小batch mean和小batch variance进行all_gather操作,每个进程都得到全局量。- 注释:只传递 mean 和 variance,而不是整体数据,可以大大减少通讯量,提高速度。
- 每个进程分别计算总体 mean 和总体 variance,得到一样的结果
- 注释:在数学上是可行的,有兴趣的同学可以自己推导一下。
- 接下来,延续正常的 BN 计算。
- 注释:因为从前向传播的计算数据中得到的
batch mean和batch variance在各卡间保持一致,所以,running_mean和running_variance就能保持一致,不需要显式地同步了!
- 注释:因为从前向传播的计算数据中得到的
- 在各进程上计算各自的
- 后向传播:和正常的一样
在代码中引入 SynvBN 也比较简单,在模型包裹成 DDP 模型前加一句话就可以了:
1 | device = torch.device("cuda:{}", local_rank) |
这样的同步 BN 可能会减慢运行速度,所有有的代码并没有使用。
关于 BN 层的处理来自知乎文章 DDP系列第三篇:实战与技巧
学习率调整
有的代码会把学习率给增大,就是多卡的学习率等于原来单卡的学习率乘卡的数量。
这一步可能不是必要,也可以在多卡训练的时候就探索设置适合多卡的学习率。
载入权重
载入权重的时候要注意设置 map_location,使得权重载入到当前这张卡上:
1 | checkpoint = torch.load(ckpt_path, map_location=device) |
4. 使用 torch.multiprocessing 取代启动器
PyTorch 把 multiprocessing 库封装成 torch.multiprocessing,可以使得单卡、DDP 下的外部调用一致,即不用使用 torch.distributed.launch。
使用时,只需要调用 torch.multiprocessing.spawn,torch.multiprocessing 就会帮助我们自动创建进程。mp.spawn 给定一个函数 main_work,开启 ngpus_per_node 个进程来执行 main_worker,main_worker 的参数通过 args 传递:
1 | mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, args)) |
main_worker 的第一个参数表示 local_rank(该参数不需要在 mp.spawn 中指定),这个必须要设置,后面的参数是自定义的:
1 | def main_worker(index, ngpus_per_node, args): |
注意在使用 mp.spawn 时,由于没有 torch.distributed.launch 读取的默认环境变量作为配置,我们需要手动为 init_process_group 指定 world_size 和 rank,这个可以参照 MoCo 的官方代码。
5. 参考资料
几个写的比较好的博客:
几个看过的视频:
一个 GitHub 仓库的 README,主要参考了 mp.spawn 相关的内容:
我对 MoCo 官方代码的注释:
官方文档:
后记
今天是 2022 年 4 月 8 号,封校自 2022 年 3 月 9 号开始,到今天正好一个月。解封的希望来了又去,现在遥遥无期,疫情到来打乱了我的计划,也让我失去了毕业后的假期(这可能是今后很长一段时间我能拥有的最长、最自由的假期了)。我恨疫情,更恨上海这帮子故意搞乱的官员。希望赶紧能有个空隙让我滚出上海的,现在到外地都需要隔离,但至少让我有个能隔离的机会。祈求。
更新记录:
- 2022-4-8:第一版上传